
VÝSTUPY Z PROJEKTU
Experimenty s 2D/3D filtráciou, 3D rekonštrukciou a vizualizáciou skenov mozgu
Bola zrealizovaná/vykonaná rešerš softvérov, ktoré možno použiť pre načítanie medicínskych dát uložených v štandardizovanom formáte DICOM. Ten umožňuje v kompaktnej forme uchovávať rôzne sekvencie snímkou z rôznych uhlov a pohľadov. Existuje viacero komerčných softvérov, ktoré vyžadujú platenú licenciu. Zamerali sme sa na tie, ktoré nemajú časové obmedzenie pre skúšobné použitie. Pre našu prácu overenie správnosti dát sme použili MicroDicom Viewer – bez časového obmedzenia pre nekomerčné využitie. Zaujímavým softvérom pre analýzu je 3D Slicer - je schopný generovať 3D model, za predpokladu, že má k dispozícii snímky z rôznych rovín pohľadu.
Dáta ktoré sme spracovávali, boli na báze röntgenových snímkou hlavy snímaných z rôznych uhlov po oblúku. V tomto prípade 3D Slicer nedokáže vytvoriť 3D model. Každý set pacienta obsahoval 122 snímkou s rotáciou po oblúku v rozsahu 0-210 stupňov. V spolupráci s Rádiologickou klinikou JLF UK a UNM sme mali k týmto snímkam navyše textové anotácie, ktoré vykonal lekár špecialista samostatne pre každý snímok (Obr. 1).

Obr. 1 Ukážka snímok zobrazených z dvoch rôznych uhlov. Červený obdĺžnik reprezentuje manuálnu anotáciu prítomnej aneuryzmy.
Spracovanie dát sme realizovali vo vývojom prostredí pre Python. Pre načítanie a spracovanie DICOM dát sme použili nasledujúce knižnice: pydicom, numpy, cv2, math a matplotlib.

Obr. 2 Obraz pred filtráciou a po vykonaní adaptívneho binárneho threshold-u.
Pre zvýraznenie ciev sa musí použiť kontrastná látka, ktorú dokáže zaznamenať RTG, inak by cievy splynuli s ostatným mäkkým tkanivom. Pre strojovú analýzu by bolo optimálne, ak by v obraze zostali len samotné cievy. Adaptívnou filtráciou sa snažíme odstrániť z obrazu tkanivá, ktoré nie sú pre analýzu relevantné. Obr. 2 znázorňuje výsledok adaptívnej filtrácie s binárnym threshold-om.
Na vytvorenie 3D modelu nie je možné využiť softvér 3D Slicer, nakoľko neumožňuje vytvoriť trojrozmerný z daného typu dát. Zrealizovali sme vlastný algoritmus, ktorý vychádza zo znalostí, že z sekvencia obrazov je vytvorená rotáciou okolo hlavy, kde centrum rotácie sa nachádza v strede hlavy. Rotácia prebieha pozdĺž vertikálnej osy Y. Os Y sa mapuje v 3D obraze lineárne, kým os Z a X sa prepočítava z polárnych súradníc.

Obr. 3 Príklad mapovania snímkou. Každá čiara reprezentuje 2D snímky pri pohľade zhora (Pre lepšiu ilustráciu je znázornená len 1/4 z celkového počtu). Pozícia na osy X a uhol otočenia predstavujú polárne súradnice pre rovinu X, Z.
Zo schémy mapovania snímky možno vidieť, že body v okolí osi otáčania budú hustejšie mapované ako na okrajoch (Obr. 3). Farebne rozlišujeme pohľady snímané z pravej časti tváre modrou a ľavú polovicu predstavujú zelené snímky. Ako centrálny uhol sa zobral pohľad na tvár spredu. Pre mapovanie sme obmedzili uhly pohľadu na rozsahu 180° z pôvodných 210°.

Obr. 4 Znázornenie 3D modelu dát, ktoré reprezentujú tkanivo určené na detekciu aneuriziem.
Výsledná matica predstavuje logické trojrozmerné pole, kde každý bod pola reprezentuje prítomnosť alebo neprístomnosť tkaniva určeného na analýzu. Za ideálnych podmienok by matica obsahovala len pozície prítomnosti ciev. Súčasný model (Obr. 4) obsahuje aj rušivé artefakty ako hranice kostí lebky, očné oblučnice, zuby, zubné výplne a pod.
Vytvorenie nástroja na jednoduchú anotáciu aneuryziem pre lekárov
Na riešenie tejto úlohy sme využili programovací jazyk Python, v ktorom je náš anotačný nástroj naprogramovaný. Samotný anotačný nástroj, slúži na vytvorenie anotácií dát/lekárskych záznamov pacientov.

Obr. 5 Postup anotácie dát
Postup anotácie (Obr. 5):
Anotačný nástroj následne ku každej snímke na ktorej sú vytvorené anotácie vytvorí nový súbor do ktorého zapíše súradnice anotácie. Tento program bol poskytnutý doktorom, ktorý jeho využitím anotovali niekoľko setov záznamov. Jeden set obsahuje 122 snímok, ktoré boli vytvorené v 360 stupňovej projekcii. Na základe týchto dát je v budúcnosti možné vytvoriť aj 3D model samotného skenu. Následne je stále možné použiť anotácie s 2D priestoru a vytvoriť tak 3D anotáciu preložením jednotlivých anotácie (Obr. 6).
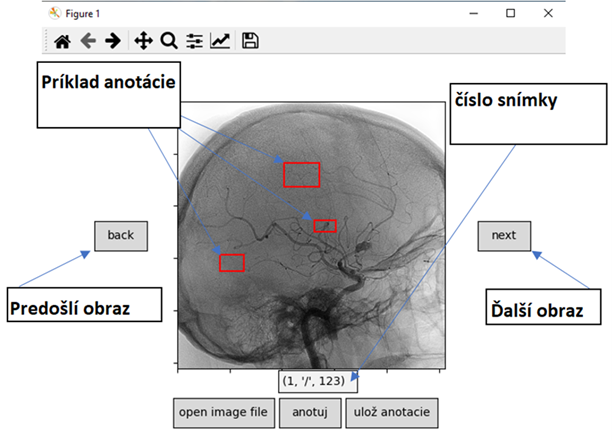
Obr. 6 Príklad práce v anotačnom nástroji.
Detekcia aneuryziem využitím hlbokého učenia
V rámci detekcií aneuryziem sme sa rozhodli navrhnúť a aplikovať neurónové siete, ktoré sa využívajú pre klasifikáciu aneuryziem ale zároveň sme navrhli aj siete, ktoré nie sú tak často používané. Pracovali sme s tromi architektúrami neurónových sieti (PointCNN, dve navrhnuté architektúry - 3DCNN a 2DCNN) [Yang2020], [Charl2017], [Krizh2012], [Demi2019].
Hierarchická aplikácia konvolúcií je nevyhnutná pre učenie sa hierarchických reprezentácií cez CNN. PointCNN zdieľa rovnaký dizajn a zovšeobecňuje ho na mračná bodov. Predstavíme si hierarchické konvolúcie v PointCNN, analogicky k obrazovým CNN, jadroOperátor X-Conv a nakoniec architektúry PointCNN. V pravidelných mriežkach sa konvolúcie aplikujú rekurzívne na lokálnych mriežkových centrách, čo často znižuje rozlíšenie mriežky (4x4⇥3x3 ⇥ 2x2). Podobne je to aj v mračnách bodov využitím X-Conv na skupiny susediacich bodov. Body s menšou informáciu sa pričítajú k tým bodom s väčšou informáciou. Obr. 7. Inými slovami povedané PointCNN sa líši od klasických CNN použitím vrstvy X-Conv. Hlavné dva rozdiely sa týkajú nasledovných bodov:
Proces prevodu súradníc bodu na prvky. Susedné body sú transformované na miestne súradnicové systémy reprezentatívnych bodov. Miestne súradnice každého z nich bod sa potom jednotlivo zdvihne a skombinuje s príslušnými prvkami. Je dôležité si všimnúť, že počet trénovacích vzoriek pre najvyššie vrstvy X-Conv rýchlo klesá (Obr. 8a). Na vyriešenie tohto problému sa navrhuje PointCNN s hustejším spojenia (Obr. 8b), kde je vo vrstvách X-Conv ponechaných viac reprezentatívnych bodov. Však naším cieľom je zachovať hĺbku siete pri zachovaní rýchlosti rastu vnímavého poľa, a to tak, že hlbšie reprezentatívne body „vidia“ čoraz väčšie časti celého tvaru. Tento cieľ dosahujeme využitím rozšírenej konvolúcie z CNN v PointCNN. Táto metóda pracuje nad point cloud reprezentáciou tak, že sa na jednotlivé body pozerá ako na množinu, teda body v nej sú nezoradené. Sieť bola navrhnutá tak, aby bola schopná odhadnúť kategóriu objektu a taktiež segmentovať model. Na odhadnutie kategórie by stačilo extrahovať globálne rysy. Segmentácia však vyžaduje aj extrakciu lokálnych rysov. To je dosiahnuté tak, že k rysom extrahovaným pre každý bod sa pripoja globálne rysy a z týchto vektorov sa sieť učí ďalšie rysy pre každý bod tak, aby v nich bola zahrnutá ako lokálna, tak globálna informácia. Výhodou PointCNN pre klasifikáciu aneuryziem je, že môže rozpoznávať objekty v 3D priestore, bez ohľadu na ich rotáciu a transformáciu.
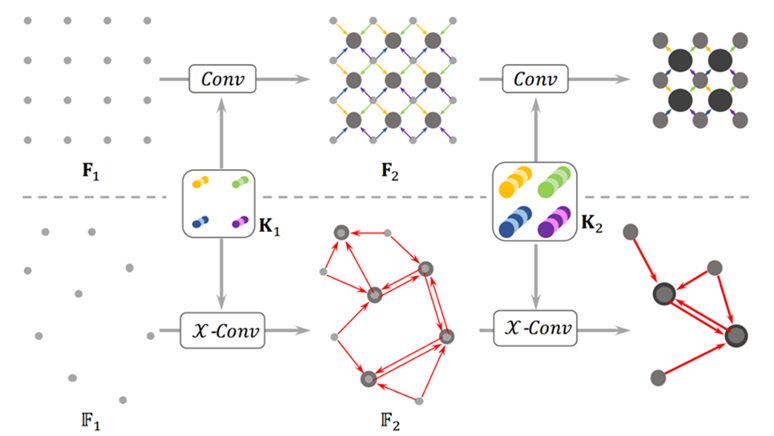
Obr. 7 Hierarchická konvolúcia na pravidelnej mriežky a mračná bodov.
V druhej vrstve X-Conv PointCNN (Obr. 8b) sa používa rýchlosť dilatácie D = 2, takže všetky štyri zostávajúce reprezentatívne body „vidia“ celý tvar. Týmto spôsobom môžeme dôkladnejšie trénovať najvyššie vrstvy X-Conv, pretože v sieti je zapojených oveľa viac spojení v porovnaní s PointCNN. V testovacom čase sa výstup z viacerých reprezentatívnych bodov spriemeruje tesne pred soft max, aby sa stabilizovala predpoveď. Tento dizajn je podobný dizajnu Network in Network.

Obr. 8 Vzory PointCNN architektúry.
Pre segmentačné úlohy je potrebný bodový výstup s vysokým rozlíšením, čo je možné realizovať vybudovaním PointCNN podľa architektúry Conv-DeConv , kde časť DeConv je zodpovedná za šírenie globálnych informácií do predpovedí s vysokým rozlíšením (Obr. 8c). „Conv“ aj „DecConv“ v segmentačnej sieti PointCNN sú tým istým operátorom X-Conv. Jediný rozdiel medzi vrstvami „Conv“ a „DeConv“ je v tom, že druhá vrstva má viac bodov, ale menej kanálov funkcií vo svojom výstupe v porovnaní so vstupom, a jej body s vyšším rozlíšením sa prenášajú zo starších vrstiev „Conv“ podľa návrhu U-Net.
Architektúra 2DCNN
Architektúra tejto (Obr. 9) siete sa skladá z piatich 2DCNN vrstiev, kde sme sa inšpirovali PointCNN a zvyšovali sme počet filtrov v každej vrstve. Tak isto ako v PointCNN sme zakončili architektúru vrstvou, ktorá ma 1024 filtrov. Každá jedna vrstva 2DCNN, sa skladá z určeného počtu filtrov a veľkosti kernela, ktorí je vo všetkých prípadoch rovnaký 3x3. V prvej vrstve máme 32 filtrov a vkladáme tak isto na vstup mračno bodov. Druhá 2CNN vrstva ma 64 filtrov, tretia 12 a štvrtá 512 filtrov. 2DCNN vrstva vykonáva priestorovú konvolúciu nad obrázkami. Táto vrstva vytvára konvolučné jadro, ktoré sa konvolvuje so vstupom vrstvy a vytvára tenzor výstupov. Na konci architektúry sa nachádzajú dense a flatten vrstvy. Dense vrstva je vrstva plne prepojených neurónov a flatten vrstva vytvorí výstupný vektor z architektúry.

Obr. 9 Štruktúra navrhnutej 2DCNN siete.
Architektúra 3DCNN
Následne sme navrhli architektúru siete typu 3DCNN (Obr. 10), ktorá sa používa na klasifikáciu 3D medicínskych dát. Architektúra sa skladá z 3DCNN vrstiev. 3DCNN vrstva aplikuje posuvné kubické konvolučné filtre na 3D vstup. Vrstva konvoluje vstup posúvaním filtrov pozdĺž vstupu vertikálne, horizontálne a pozdĺž hĺbky, výpočtom bodového súčinu váh a vstupu a následným pridaním skreslenia.
Architektúra sa skladá z dvoch 3DCNN vrstiev a dvoch MaxPooling3D vrstiev. Obe 3DCNN vrstvy majú 64 filtrov a kernel 3x3x3. Obe maxpooling3D vrstvy majú kernel 2x2x2. Na konci architektúry sa taktiež nachádzajú vrstvy Dense a Flatten. Maxpoolin3D je operácia združovania pre 3D údaje (priestorové alebo priestorovo-časové). Znižuje vzorkovanie vstupu pozdĺž jeho priestorových rozmerov (hĺbka, výška a šírka) tak, že pre každý kanál vstupu zoberie maximálnu hodnotu vo vstupnom okne (s veľkosťou definovanou hodnotou kernel).
Následne sme na základe rovnakých podmienok tieto tri architektúry trénovali a testovali. Na vstup sme vkladali mračno bodov o veľkosti 64x64x64. Následne prebiehalo trénovanie, kde sa neurónova sieť mala naučiť na základe anotácie, kde sa nachádzajú tepny bez aneuryziem a tepny s aneuryzmami. Nakoľko sú dáta rozdelené v pomere 70:20:10 (Trénovacia: Testovacia: Validačná), testovanie prebieha na iných dátach ako trénovanie. Následne po trénovaní sme získali výsledky, ktoré môžete vidieť v Tab. 1.
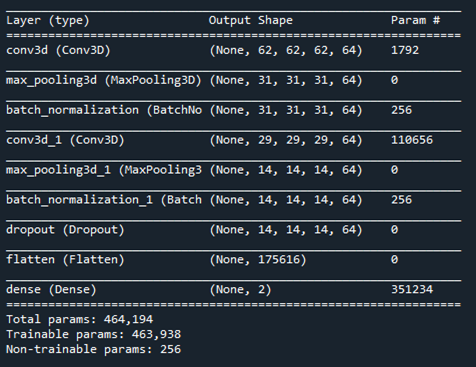
Obr. 10 Štruktúra navrhnutej 3DCNN siete.
Tab. 1 Porovnanie navrhnutých architektúr (2DCNN a 3DCNN) s existujúcimi riešeniami.
| Presnosť klasifikácie [%] | ||||
|---|---|---|---|---|
| Tepna | Aneuryzma | F1-Skóre [%] | ||
| PN++ | 98.52 | 86.69 | 89.26 | |
| SpiderCNN | 98.05 | 84.58 | 86.92 | |
| SO-Net | 98.76 | 84.24 | 88.40 | |
| PointCNNt | 98.38 | 78.25 | 84.94 | |
| DGCNN | 95.22 | 60.73 | 65.78 | |
| PointNet | 94.45 | 67.66 | 69.09 | |
| Navrhnutá 2DCNN | 97.61 | 72.72 | 86.61 | |
| Navrhnutá 3DCNN | 98.81 | 68.18 | 87.14 | |
Referencie:
[Yang2020] Yang, Xi and Xia, Ding and Kin, Taichi and Igarashi, Takeo, IntrA: 3D Intracranial Aneurysm Dataset for Deep Learning, The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
[Charl2017] R. Charles, H. Su, M. Kaichun and L. Guibas, PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In:. July 2017, pp. 77–85, 2017.
[Krizh2012] A. Krizhevsky, I. Sutskever and G. E. Hinton: „ImageNet Classification with Deep Convolutional Neural Networks”, In Advances in Neural Information Processing Systems, NIPS, vol. 25, 2012.
[Demi2019] A. Demir, F. Yilmaz and O. Kose: „Early detection of skin cancer using deep learning architectures: resnet-101 and inception-v3”, 2019 Medical Technologies Congress (TIPTEKNO), Izmir, Turkey, 2019, pp. 1-4, doi: 10.1109/TIPTEKNO47231.2019.8972045.